I pondered the mysterious of life and the funny ways that people choose to attack a problem.
Like, why, given a task to get data from A to B, with the option of doing 'stuff' to it in the process, they choose to park the connection data in a database. Maps, settings for how the server talks to which and who is connected. Queries written in a proprietary language (close to but not quite SQL). All stuffed into a database.
This feels wildly sub-optimal. Was this state of the art ten years ago? What were we thinking?
Now, yes, I can see why you would want to store transaction data in a database. Although for as much use as we put that data to we might as well send it to /dev/null.
Which Windows ain't got but there you go.
But I also had fun - I downloaded Openadaptor and fired up the examples.
From the tutorial
Now fire up the included test.html page
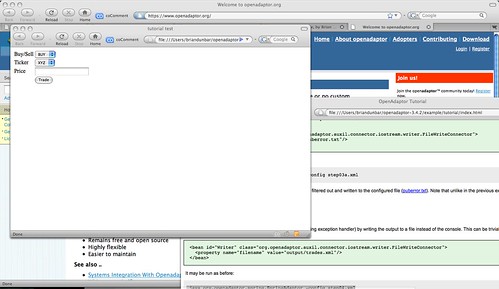
Enter a dollar amount, push enter and it writes xml data to the file location defined in step04.xml.
The best part - to me - is that this is a solution that scales in a way that (say) a Visual Basic written application can't.
Define a new connection in xml. Mount it on an NFS share so you can run it from multiple servers. Launch it from shell. Schedule it with cron. Get hardcore and use an enterprise scheduler. Run the proc in the background if it's going to take a while. Stuff like this is what unix is good at.
Of course, the chances of this making it from my laptop (or even my hip-pocket develoment server) to an actual Project are slim to none, but there you go.
Like, why, given a task to get data from A to B, with the option of doing 'stuff' to it in the process, they choose to park the connection data in a database. Maps, settings for how the server talks to which and who is connected. Queries written in a proprietary language (close to but not quite SQL). All stuffed into a database.
This feels wildly sub-optimal. Was this state of the art ten years ago? What were we thinking?
Now, yes, I can see why you would want to store transaction data in a database. Although for as much use as we put that data to we might as well send it to /dev/null.
Which Windows ain't got but there you go.
But I also had fun - I downloaded Openadaptor and fired up the examples.
From the tutorial
briandunbar_localhost_~/openadaptor-3.4.2/example/tutorial:java org.openadaptor.spring.SpringAdaptor -config step04.xml
INFO [main] Loading XML bean definitions from class path resource [org/openadaptor/spring/.openadaptor-spring.xml]
INFO [main] Loading XML bean definitions from URL [file:step04.xml]
(snip)
Now fire up the included test.html page
Enter a dollar amount, push enter and it writes xml data to the file location defined in step04.xml.
The best part - to me - is that this is a solution that scales in a way that (say) a Visual Basic written application can't.
Define a new connection in xml. Mount it on an NFS share so you can run it from multiple servers. Launch it from shell. Schedule it with cron. Get hardcore and use an enterprise scheduler. Run the proc in the background if it's going to take a while. Stuff like this is what unix is good at.
Of course, the chances of this making it from my laptop (or even my hip-pocket develoment server) to an actual Project are slim to none, but there you go.